


Introduction In the vast ocean of the internet, valuable data is often presented in organized lists: product inventories, directories, search resu
Introduction
In the vast ocean of the internet, valuable data is often presented in organized lists: product inventories, directories, search results, event schedules, and more. Extracting this data manually is tedious and inefficient, especially when dealing with large datasets. Enter lists crawlers—specialized tools designed to automate the extraction of structured information presented as lists on web pages.
This article explores the fundamentals of lists crawlers, their inner workings, practical uses, challenges, and how to build or employ them effectively. Whether you’re a developer, researcher, or business professional, understanding lists crawlers can dramatically enhance your data collection capabilities.
What Exactly Is a Lists Crawler?
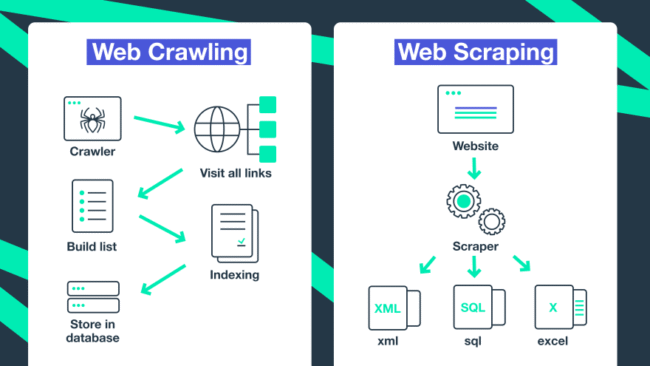
A lists crawler is a type of web scraper that targets repetitive structured data blocks on web pages, typically presented as lists or grids. Unlike generic crawlers that may scan entire sites indiscriminately, lists crawlers focus on recognizing and extracting consistent, repeated elements—such as product cards, table rows, or list items.
The advantage is precision: lists crawlers streamline the collection of multiple similar entries in one go, extracting useful fields like titles, prices, dates, descriptions, and links.
For More: lists crawler
How Do Lists Crawlers Function?
1. Initiation via Seed URLs
The crawling process starts with one or more URLs containing the target lists—such as a category page or search result.
2. Downloading Page Content
Using HTTP requests, the crawler fetches the HTML content of these pages.
3. Parsing the HTML Structure
The raw HTML is parsed into a structured format (DOM) to allow element-by-element inspection.
4. Identifying List Patterns
The crawler detects repeated HTML structures that correspond to list entries. This can be repeating <li> tags, multiple <div> elements sharing a class, or rows within <table> elements.
5. Extracting Data Points
For each list item, specific data fields are extracted using CSS selectors, XPath expressions, or regular expressions.
6. Navigating Pagination or Dynamic Loading
Lists often span multiple pages or use infinite scrolling. The crawler follows “Next” links or simulates scroll events to capture all data.
7. Cleaning and Saving Data
The extracted information is cleaned (formatting dates, trimming spaces) and saved in the desired output format for further use.
Why Use Lists Crawlers? Key Benefits
- Speed and Efficiency: Automates the extraction of vast amounts of structured data quickly.
- Accuracy: Reduces human error in manual data entry.
- Data Aggregation: Gathers data from multiple sources for comprehensive insights.
- Competitive Intelligence: Monitors competitor offerings and pricing in near real-time.
- Research Support: Provides large datasets for academic or market research.
- Business Lead Generation: Extracts contact information or company directories efficiently.
Real-World Applications of Lists Crawlers
E-commerce and Retail
Track competitor pricing, product availability, and customer reviews by scraping product lists from online stores.
Job Market Aggregation
Collect job listings across platforms to analyze trends or build aggregated job boards.
Real Estate
Extract property listings, prices, and descriptions for market analysis or client services.
Event Management
Gather event schedules, venues, and ticket availability for aggregation or resale.
Content Curation
Aggregate headlines, summaries, and article links from news websites.
Lead Generation
Extract business directories or social profiles to build targeted outreach lists.
Developing a Lists Crawler: Practical Considerations
Choose Your Tools
- Python: Libraries like BeautifulSoup, Scrapy, Selenium for dynamic content.
- JavaScript: Puppeteer or Playwright for complex, JavaScript-heavy sites.
- No-Code Platforms: Tools like Octoparse or WebHarvy for those without coding skills.
Understand the Target Site’s Structure
Analyze the HTML to identify the container elements for list items and target fields.
Pagination Handling
Implement logic to detect and follow pagination links or load more items on infinite scroll.
Data Cleaning
Normalize extracted data (dates, currency formats), remove duplicates, and validate for accuracy.
Storage Solutions
Choose between CSV files, JSON, SQL/NoSQL databases, or cloud storage depending on volume and use case.
Sample Python Script for a Simple Lists Crawler
python
CopyEdit
import requests
from bs4 import BeautifulSoup
def extract_list_data(url):
headers = {‘User-Agent’: ‘Mozilla/5.0’}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, ‘html.parser’)
list_items = soup.find_all(‘div’, class_=’item-container’)
results = []
for item in list_items:
title = item.find(‘h3′, class_=’item-title’).get_text(strip=True)
price = item.find(‘span’, class_=’item-price’).get_text(strip=True)
results.append({‘title’: title, ‘price’: price})
return results
if __name__ == “__main__”:
url = ‘https://example.com/products/page1’
data = extract_list_data(url)
for entry in data:
print(f”{entry[‘title’]} – {entry[‘price’]}”)
Expand this example with pagination and error handling for real-world use.
Common Challenges When Using Lists Crawlers
- Website Structural Changes: Frequent HTML updates can break your crawler.
- JavaScript-Rendered Content: Requires headless browsers or API reverse engineering.
- Anti-Scraping Mechanisms: CAPTCHAs, IP bans, rate limiting may block crawlers.
- Legal Restrictions: Terms of service and data privacy laws impose limits.
- Data Quality Issues: Incomplete or inconsistent data requires post-processing.
Best Practices for Successful Lists Crawling
- Respect Robots.txt and Legal Boundaries: Always check website policies.
- Implement Request Throttling: Avoid overloading target servers.
- Rotate IPs and User Agents: Reduce the risk of blocking.
- Use Headless Browsers When Necessary: Handle dynamic content gracefully.
- Monitor and Update Regularly: Ensure crawler keeps working as sites change.
- Maintain Data Hygiene: Validate and clean data post-extraction.
- Document and Log Crawling Activities: Useful for debugging and audits.
Advanced Techniques and Tools
- Machine Learning for Pattern Detection: Use AI to adaptively identify list patterns.
- Distributed Crawling: Scale scraping by distributing tasks across servers.
- API Utilization: Sometimes data is accessible via undocumented APIs—using these can be more reliable than scraping HTML.
- Captcha Solvers: For unavoidable CAPTCHAs, services or algorithms may be employed (use ethically).
FAQs
Q1: Can lists crawlers handle all types of web lists?
Mostly yes, but JavaScript-heavy or highly dynamic lists require advanced tools like headless browsers.
Q2: Do I need programming skills to use lists crawlers?
Not necessarily. Many no-code tools allow building crawlers with minimal technical expertise.
Q3: How do I deal with infinite scrolling pages?
Use headless browsers to simulate scrolling or analyze network requests to retrieve data APIs.
Q4: Is web scraping legal?
Scraping publicly available data is often legal, but it depends on the website’s terms and jurisdiction. Always check and respect legal guidelines.
Q5: What are common formats for storing scraped data?
CSV, JSON, Excel, and databases are the most common formats.
Q6: Can I automate periodic crawling?
Yes, scheduling tools or scraping platforms support automation and regular data updates.
Q7: How do I ensure my crawler isn’t blocked?
Use proxies, rotate user agents, add delays, and avoid excessive request rates.
Conclusion
Lists crawlers unlock access to a wealth of structured web data by automating extraction from repetitive elements on web pages. They are invaluable across industries for market research, competitive analysis, lead generation, and much more.
By understanding how lists crawlers work, choosing the right tools, and following best practices, you can efficiently harness web data while navigating technical and ethical challenges. Whether you’re a developer looking to build a custom crawler or a business seeking ready-made solutions, lists crawlers empower you to tap into the vast data resources of the internet.
Ready to dive deeper or need tailored advice? Just ask—I’m here to help!
For More Info: onlinemrkting
COMMENTS